
Keeping track of your DNA matches can be a chore. With new matches popping up all the time, it’s hard to remember who you’ve already seen and what relationships you’ve already researched.
This is further complicated when you’re trying to manage multiple kits across multiple testing companies. This article will teach you how to make a spreadsheet for your DNA matches, and provide a template to get started.
In a hurry? You can access my spreadsheet template here.
To learn more about DNA testing and genetic genealogy, read this guide.
Before we dive into the fine details, let’s talk about some reasons why you would want to track your matches.
Stay organized
Because I manage multiple kits across multiple company databases, I need a system to keep track of my activities. But I don’t just add my matches to a spreadsheet to have a nice clean list of people.
I track which matches I’ve determined the actual relationship for and which I have not. That way, when I have some free time and want to sink my teeth into a new DNA mystery, I open my list and filter by unidentified matches.
I’m also a big fan of “painting” my matches on a Friday night. By that, I mean I’m a big fan of DNA Painter’s chromosome mapping tool. I like to think of this tool as a single chromosome browser for all my matches. Keeping track of who I’ve added to this tool allows me to see who I still need to add.
Unlike some other spreadsheet templates, I don’t like to store chromosome data or start/stop positions in my spreadsheet. DNA Painter is a far better tool for this, so there’s no need for redundancy. I like to track who I’ve already painted – even if I haven’t determined the common ancestor(s).
Some other essential things I like to track are contact information, strong shared matches, and notes. The notes field I leave open-ended, which allows me to make a note of any other pertinent information not covered by the other fields. This is where I can record things like a Gedmatch kit ID, links to research logs in google docs, or links to trees I created on Lucidchart.
I also use my spreadsheet to quickly group my match list across all databases by things like MRCA (most recent common ancestors) and actual relationships. Grouping matches like this is one reason I use AirTable instead of Microsoft Excel or Google Docs (more on that later).
Log it before you lose it.
Another fundamental reason to track your DNA matches with a spreadsheet is that not everyone keeps their profiles active forever. When news broke of police using DNA databases to hunt down the Golden State Killer, many people removed their profiles due to privacy concerns. I lost a lot of valuable match information when that happened, especially on Gedmatch. In particular, one match was a heartbreaking loss because it was critical to the brick wall case I was working on. That loss is what prompted me to start keeping track of my matches.
Companies like 23andMe, MyHeritage, and FamilyTreeDNA allow you to view chromosome detail for your matches. If the match removes their profile or makes it private before you log that information, you’ve lost it. This is especially true on 23andMe. Many people opt for private profiles since their health information is linked to the same account.
Using Airtable
My spreadsheet application of choice is Airtable. If you haven’t heard of this app before, it’s a combination of Microsoft Excel and Microsoft Access. You’re getting the same easy-to-use spreadsheet interface, but with relational database capabilities. This allows you to manipulate your data any which way. I love Airtable.
Using the spreadsheet
Let’s take a look at my DNA match spreadsheet template and how to use it. Feel free to customize to your specific needs.
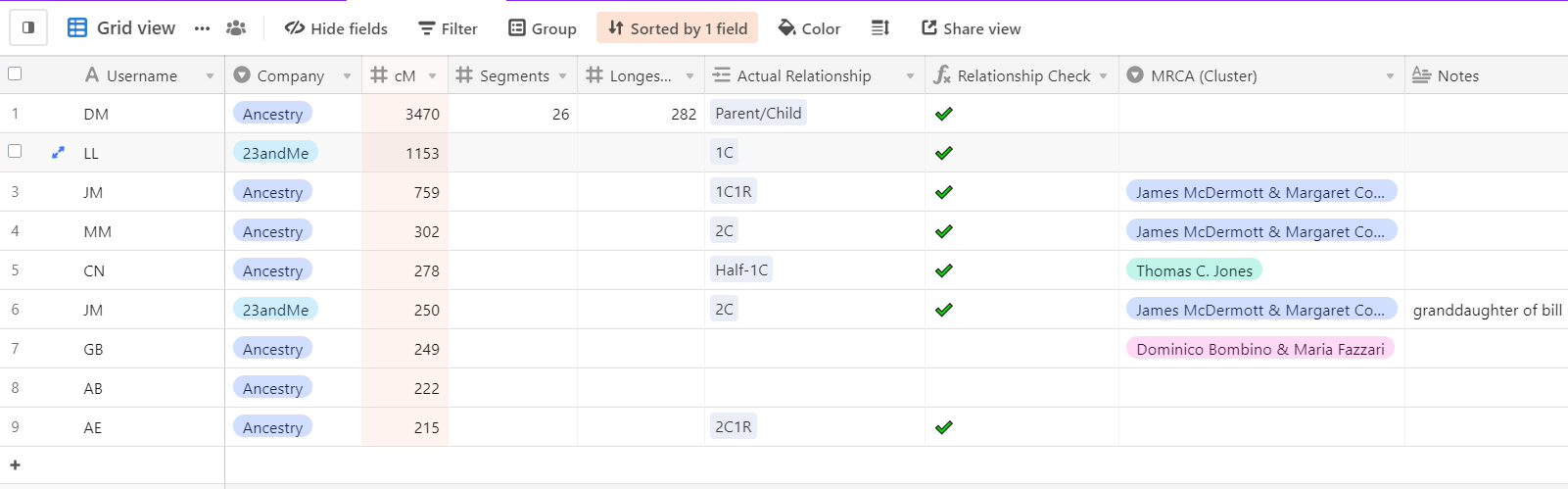
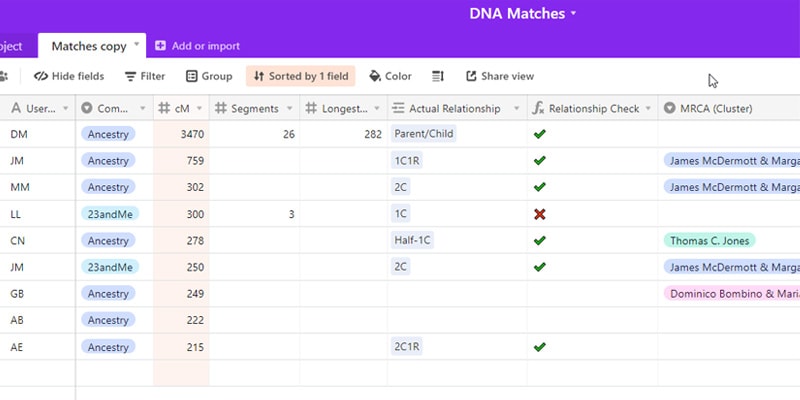
The first column is the username of the match. I track by username instead of the real name to easily find them later in whichever company database they’re in.
Speaking of company database, the second column is just that. Not only is this a good thing to track so you can easily find the match later, but some people will be in multiple databases, and you’ll want to track that. For example, suppose you have a match on Ancestry. In that case, you can’t paint that match on DNAPainter because Ancestry doesn’t show chromosome data. But if that match then joins a site that offers chromosome data, we need to record that and immediately log the data before it’s lost. Currently, there are options for Ancestry.com, MyHeritage, Family Tree DNA, 23andMe, LivingDNA, and Gedmatch.
The next three columns have to do with the amount of shared DNA and segments. I look at:
- Total shared centimorgans (most important)
- Number of segments
- Longest segment (in centimorgans)

I use this data to compute if the actual relationship I’ve identified with each match is even possible. How do I do that? The column after the shared DNA numbers is Actual Relationship. This is the relationship that I’ve determined based on genealogical research – not the predicted relationship given by the testing company. Once I input an actual relationship, my spreadsheet will compute if it’s possible given the amount of shared DNA. It uses data from the Shared Centimorgan Project to determine if the total shared centimorgans are in the actual relationship range.
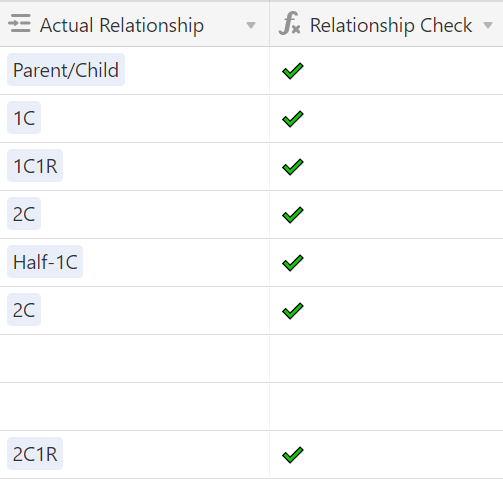
So if I add a match who I determined to be my first cousin and we share 300 cM, the “Relationship Check” column will show a red X indicating that’s not possible. First cousins need to share at least 400 cM.
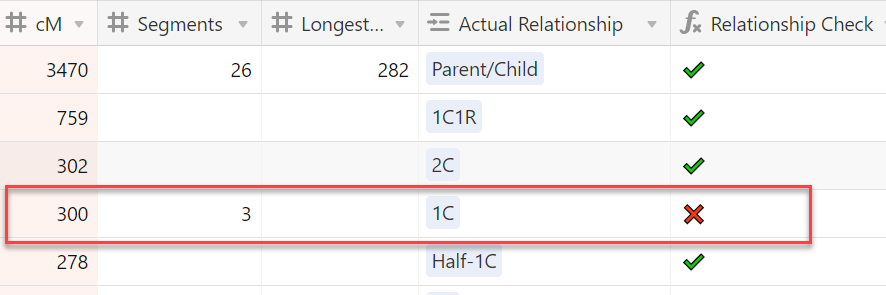
I will note here that my spreadsheet does not calculate probabilities or take into account outliers. For that, I recommend using the Shared CM Tool at DNA Painter. My spreadsheet (for now) focuses on what’s possible – not probabilities.
The next column is the MRCA. This is where you add or select the common ancestor(s) from your family tree once you’ve concluded your research with each match. You can then group your matches by this field to see all matches, across all databases, clustered together with each MRCA.
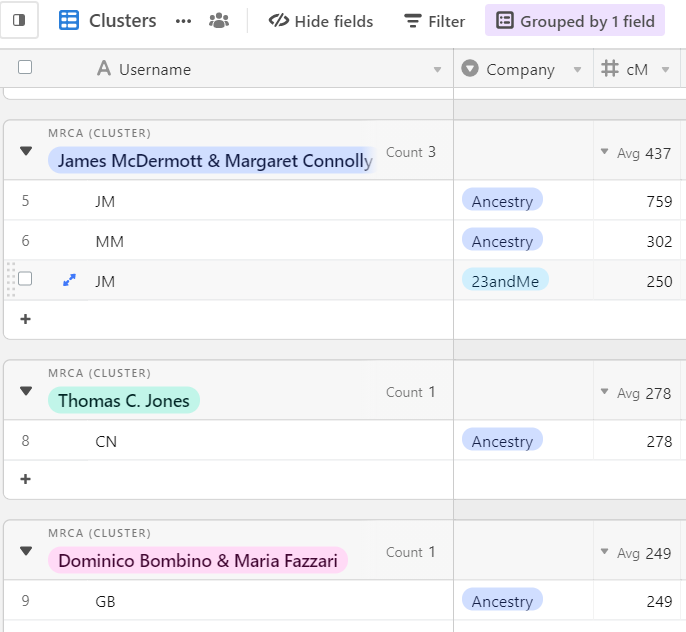
After MRCA, we have the Matches field. While I intend to expand this field’s functionality in the future, I’m only using this field to record the strongest shared matches – usually above 70 cM. This field is linked to the first column, so you’re able to select existing matches quite easily. And if you’re adding a new name, it will automatically add that person as a new row to the main spreadsheet. The column after this is simply a count of how many shared matches you’ve entered into the Matches field.
Next is the notes field. As we already talked about, this is a long-form, open-ended field where you can add anything you want: Gedmatch kits, links, funny anecdotes, whatever. Often I’ll use this field to record how the person descends from the MRCA. I like this open-ended notes field because the alternative is to have many optional columns that make the spreadsheet feel cluttered.
Next is contact info. This is another open-ended field where you can add anything you want—email address, phone number, location, etc.
Finally, we have the ‘Painted’ field. As discussed above, this is a yes/no checkbox to indicate whether the match has been added to DNA Painter.
How to make your own spreadsheet
To start using this table, create a free account with Airtable. Once set up, you can access the template here: https://airtable.com/universe/exphJMwTsAiNL2WIx/dna-matches.
Click on “Explore Base, then “Copy base” to start using for your own matches.
Final thoughts…
So there you have it—my spreadsheet for tracking DNA matches. Let me know in the comments below if you’re using the template. Feedback and constructive criticisms are always welcome!

Thank you, just learning Airtable but this one seems more doable, less clutter. Can’t wait to give it a try.
Thank you for this information. I haven’t figured out this DNA stuff yet. I would like to clarify if this AirTable Database is something you can put onto your computer and work from it there, of is this strictly used from loging into AirTable and using it from their website?
Hi Patty. You have to access it from their website.
I have tried to initiate this having already tried on an excel sheet but I am just trying to work on my maternal grandfather but I just didn’t know where to go with the fields offered.
I can’t wait to use this template. There is some much more I need to know. I have a question, I’ve been tracing ancestors and some are Native American, maybe not a question ‘but a thought, a space for their population, incase you know what it is incase you know it. Thank you very much you have been a great help to me.
Thanks I’ll consider adding that.
Thank you for this. I was going to write and ask if you knew of any databases, spreadsheets don’t do what I want. I will certainly be using this, starting now